
Learning from rewards seems like the simplest thing. I make coffee, I sip coffee, I’m happy. My brain registers “brewing coffee” as an action that leads to a reward.
That’s the guiding insight behind deep reinforcement learning, a family of algorithms that famously smashed most of Atari’s gaming catalog and triumphed over humans in strategy games like Go. Here, an AI “agent” explores the game, trying out different actions and registering ones that let it win.
Except it’s not that simple. “Brewing coffee” isn’t one action; it’s a series of actions spanning several minutes, where you’re only rewarded at the very end. By just tasting the final product, how do you learn to fine-tune grind coarseness, water to coffee ratio, brewing temperature, and a gazillion other factors that result in the reward—tasty, perk-me-up coffee?
That’s the problem with “sparse rewards,” which are ironically very abundant in our messy, complex world. We don’t immediately get feedback from our actions—no video-game-style dings or points for just grinding coffee beans—yet somehow we’re able to learn and perform an entire sequence of arm and hand movements while half-asleep.
This week, researchers from UberAI and OpenAI teamed up to bestow this talent on AI.
The trick is to encourage AI agents to “return” to a previous step, one that’s promising for a winning solution. The agent then keeps a record of that state, reloads it, and branches out again to intentionally explore other solutions that may have been left behind on the first go-around. Video gamers are likely familiar with this idea: live, die, reload a saved point, try something else, repeat for a perfect run-through.
The new family of algorithms, appropriately dubbed “Go-Explore,” smashed notoriously difficult Atari games like Montezuma’s Revenge that were previously unsolvable by its AI predecessors, while trouncing human performance along the way.
It’s not just games and digital fun. In a computer simulation of a robotic arm, the team found that installing Go-Explore as its “brain” allowed it to solve a challenging series of actions when given very sparse rewards. Because the overarching idea is so simple, the authors say, it can be adapted and expanded to other real-world problems, such as drug design or language learning.
Growing Pains
How do you reward an algorithm?
Rewards are very hard to craft, the authors say. Take the problem of asking a robot to go to a fridge. A sparse reward will only give the robot “happy points” if it reaches its destination, which is similar to asking a baby, with no concept of space and danger, to crawl through a potential minefield of toys and other obstacles towards a fridge.
“In practice, reinforcement learning works very well, if you have very rich feedback, if you can tell, ‘hey, this move is good, that move is bad, this move is good, that move is bad,’” said study author Joost Huinzinga. However, in situations that offer very little feedback, “rewards can intentionally lead to a dead end. Randomly exploring the space just doesn’t cut it.”
The other extreme is providing denser rewards. In the same robot-to-fridge example, you could frequently reward the bot as it goes along its journey, essentially helping “map out” the exact recipe to success. But that’s troubling as well. Over-holding an AI’s hand could result in an extremely rigid robot that ignores new additions to its path—a pet, for example—leading to dangerous situations. It’s a deceptive AI solution that seems effective in a simple environment, but crashes in the real world.
What we need are AI agents that can tackle both problems, the team said.
Intelligent Exploration
The key is to return to the past.
For AI, motivation usually comes from “exploring new or unusual situations,” said Huizinga. It’s efficient, but comes with significant downsides. For one, the AI agent could prematurely stop going back to promising areas because it thinks it had already found a good solution. For another, it could simply forget a previous decision point because of the mechanics of how it probes the next step in a problem.
For a complex task, the end result is an AI that randomly stumbles around towards a solution while ignoring potentially better ones.
“Detaching from a place that was previously visited after collecting a reward doesn’t work in difficult games, because you might leave out important clues,” Huinzinga explained.
Go-Explore solves these problems with a simple principle: first return, then explore. In essence, the algorithm saves different approaches it previously tried and loads promising save points—once more likely to lead to victory—to explore further.
Digging a bit deeper, the AI stores screen caps from a game. It then analyzes saved points and groups images that look alike as a potential promising “save point” to return to. Rinse and repeat. The AI tries to maximize its final score in the game, and updates its save points when it achieves a new record score. Because Atari doesn’t usually allow people to revisit any random point, the team used an emulator, which is a kind of software that mimics the Atari system but with custom abilities such as saving and reloading at any time.
The trick worked like magic. When pitted against 55 Atari games in the OpenAI gym, now commonly used to benchmark reinforcement learning algorithms, Go-Explore knocked out state-of-the-art AI competitors over 85 percent of the time.
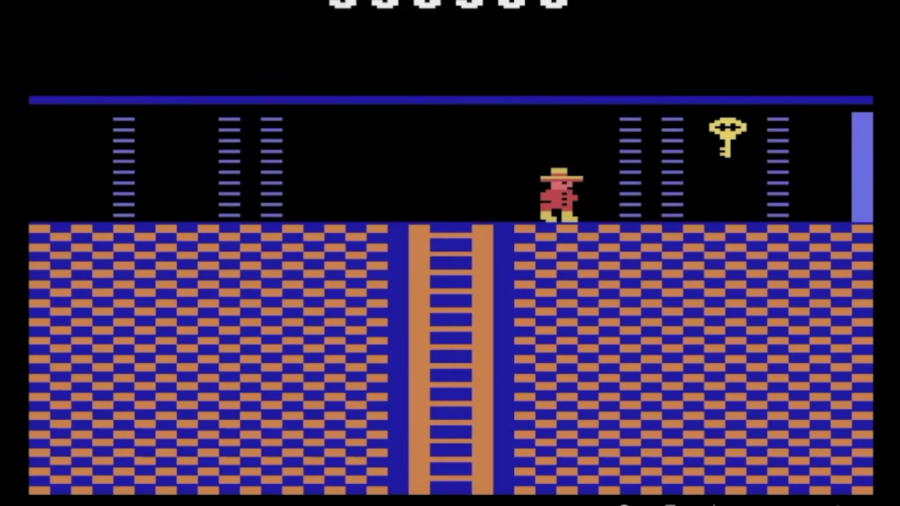
It also crushed games previously unbeatable by AI. Montezuma’s Revenge, for example, requires you to move Pedro, the blocky protagonist, through a labyrinth of underground temples while evading obstacles such as traps and enemies and gathering jewels. One bad jump could derail the path to the next level. It’s a perfect example of sparse rewards: you need a series of good actions to get to the reward—advancing onward.
Go-Explore didn’t just beat all levels of the game, a first for AI. It also scored higher than any previous record for reinforcement learning algorithms at lower levels while toppling the human world record.
Outside a gaming environment, Go-Explore was also able to boost the performance of a simulated robot arm. While it’s easy for humans to follow high-level guidance like “put the cup on this shelf in a cupboard,” robots often need explicit training—from grasping the cup to recognizing a cupboard, moving towards it while avoiding obstacles, and learning motions to not smash the cup when putting it down.
Here, similar to the real world, the digital robot arm was only rewarded when it placed the cup onto the correct shelf, out of four possible shelves. When pitted against another algorithm, Go-Explore quickly figured out the movements needed to place the cup, while its competitor struggled with even reliably picking the cup up.
Combining Forces
By itself, the “first return, then explore” idea behind Go-Explore is already powerful. The team thinks it can do even better.
One idea is to change the mechanics of save points. Rather than reloading saved states through the emulator, it’s possible to train a neural network to do the same, without needing to relaunch a saved state. It’s a potential way to make the AI even smarter, the team said, because it can “learn” to overcome one obstacle once, instead of solving the same problem again and again. The downside? It’s much more computationally intensive.
Another idea is to combine Go-Explore with an alternative form of learning, called “imitation learning.” Here, an AI observes human behavior and mimics it through a series of actions. Combined with Go-Explore, said study author Adrien Ecoffet, this could make more robust robots capable of handling all the complexity and messiness in the real world.
To the team, the implications go far beyond Go-Explore. The concept of “first return, then explore” seems to be especially powerful, suggesting “it may be a fundamental feature of learning in general.” The team said, “Harnessing these insights…may be essential…to create generally intelligent agents.”
Image Credit: Adrien Ecoffet, Joost Huizinga, Joel Lehman, Kenneth O. Stanley, and Jeff Clune
* This article was originally published at Singularity Hub





0 Comments